事由
在交大資工的某個系統中,需要將使用者輸入的資料產生成 PDF 文件,在某幾位老師的名字中出現缺漏字的狀況。
例如這三個關鍵字,從肉眼看來都是正常字元,但搜尋起來數量差異非常大:
由於前者是罕用/相容性字碼,可以看到只會出現少數搜尋結果;而作為對照組的後者是同個字面的常用字碼,搜尋結果數量差異高達萬倍。
推測發生原因
先前遇過相同問題的情境,是源自於 macOS 的 Pages 匯出為 PDF 時,雖然肉眼看起來完全正常,但內部儲存的文字不如直覺所想得一樣。
例如在 Pages 中寫「更加精進自己的能力」,匯出成 PDF 後看起來完全正常,不過複製文字或是 Google 索引到的文字卻變成「更更加精進⾃自⼰己的能⼒力力」,可以看到長得一樣的字重複了兩三次。
對於不暸解其中原理的多數人而言,很可能以為兩個字完全一樣就隨意刪掉其中一個;然而對電腦而言,重複的兩個字編碼卻不同,猜錯/刪錯了就會導致資料庫搜尋時無法正常匹配。
Normalization Forms 標準化格式
由於有些字元可被拆分成許多 Component(部件),同一個字面又可以用不同編碼呈現,因此 Unicode 組織研擬了一套標準化的演算法,幫每一組字串產生唯一的字碼序列。
其中依據「標準化拆解 / 相容性拆解」、「純拆解 / 拆完再標準化組裝」兩種屬性,分為 NFD、NFC、NFKD、NFKC 四種標準化格式(通稱為 NFx),適合在不同情境使用。
| 標準化格式 | 代表意義 |
|---|---|
| NFD | 標準化拆解 |
| NFC | 標準化拆解,再標準化組裝 |
| NFKD | 相容性拆解 |
| NFKC | 相容性拆解,再標準化組裝 |
以下節錄自 UAX #15 標準附錄 範例並加以說明:
Singletons
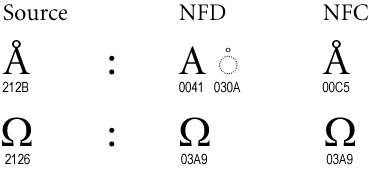
以 Å (U+212B, 埃符號) 來說,如果要轉換成 NFD 形式,會透過標準化的拆解演算法,分成 A (U+0041, 拉丁字母 A) 及 ◌̇ (U+030A, 上方圈圈) 兩個部件。
如果要轉換成 NFC 形式的話,則會先經過 NFD 程序,再透過標準化組裝得到 Å (U+00C5, 帶有上方圈圈 A 字母),而不是原本的 Å (U+212B, 埃符號)。
以 Ω (U+2126, 歐姆符號) 而言,經過 NFD 拆解演算法會找到相同字面的標準形式 Ω (U+03A9, 希臘字母 Omega),此範例中 NFC 等於 NFD。
上面兩個例子可被歸於 Singletons 類別,經過標準化後非標準的字碼會直接被標準字碼取代,不會被保留。
Multiple Combining Marks 多種組合標記
有些文字像 Ṩ 是 S 加上兩個標記符號,同一個字面也可以有多種排列組合方式
(共有 Ṩ、Ṡ + ◌̣、Ṣ + ◌̇、S + ◌̇ + ◌̣、S + ◌̣ + ◌̇ 五種)
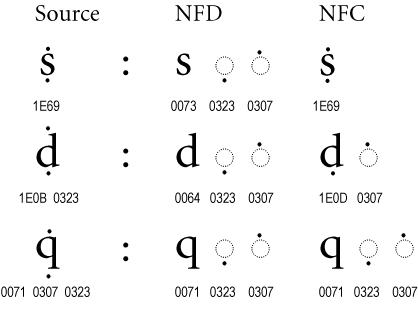
在經過 NFD 拆解後,除了將字母本體放在前面外,後面的 ◌̣ 跟 ◌̇ 也會用唯一的順序排列,保證同一串文字在經過 NFD 拆解後可以取得唯一的結果。
而用 NFC 形式在標準化組裝時,第一個例子因為有 ṩ 可以用(並且不在例外清單中),就直接用 U+1E69 單個字碼表示。
第二個例子無法用單字元表示 ḍ̇,因此在 ḍ + ◌̇ 與 ḋ + ◌̣ 之間選擇標準化的版本,以保證每次得出相同結果。
第三個例子則是因為 Unicode 字碼表內不包含 q̣ 或 q̇ 字元,因此 NFC 形式與 NFD 形式相同。
Compatibility Composites 相容性組合
前面講到了 NFD 及 NFC 兩種形式,都是使用「標準化拆解」,這邊 NFKD 及 NFKC 是使用「相容性拆解」。
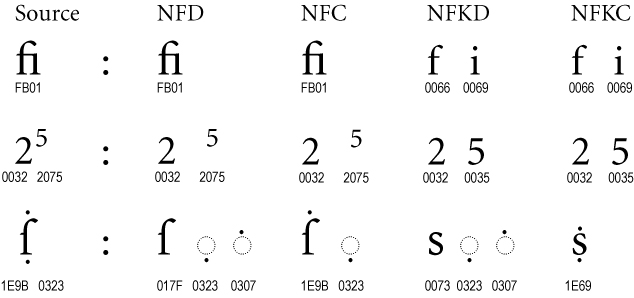
第一個例子中,原本連字的 fi 變回了 f + i 兩個字母;第二個例子把 2⁵ 的上標屬性還原,變回純數字 25。
在第三個例子中,ẛ + ◌̣ 經過相容性拆解後,把 ſ (U+017F, 拉丁小寫長版 s 字母) 變回了 s;而 NFKC 是先做相容性拆解,再做標準化組合(而不是拿 NFC 做相容性處理),因此得到單個 ṩ 而不是 ṡ + ◌̣。
小結
NFD 是 Canonical Decomposition 標準化拆解,將音標、組字拆開,再按照一套特定方法排序。
NFC 在官方文件中的定義是 Canonical Decomposition, followed by Canonical Composition,也就是先做 NFD 拆解後再組合,而不是一步到位。
而 NFKD 及 NFKC 的 K 是 Compatibility(相容性)的縮寫,會將「𝒮𝕥r𝔞𝐧g𝘦」轉換成「Strange」,得到的文字可能會長得和原文不一樣。
「o ffi c e」經過 NFD / NFC 轉換不會變,但經過 NFKD / NFKC 會變成「o f f i c e」;而「o f f i c e」經過 NFD / NFC / NFKD / NFKC 標準化都還是一樣,不會把 f f i 變成連字的 ffi。
解決方法
在經過 @splitline 指點後,得知 PHP 有內建一個函式可以完美解決這個問題。只要在需要過濾使用者輸入的地方加上 Normalizer::normalize($text); 函式,就能用 NFC 或指定的格式來標準化,讓位於其他區段的罕用字碼回到正常的常用字碼。
在各主流語言中也有相應的解法,例如 Python 的 unicodedata.normalize()、JavaScript 的 String.prototype.normalize()。
延伸閱讀 1:Confusables 易混淆字元
在研究這個問題的前期,我循線找到了 unicode-org/icu 這份 Repo,ICU 專案全名是 International Components for Unicode,包含 C/C++ 與 Java 的版本,裡面有許多 Unicode 相關字串處理的函式。
其中 confusables.txt 讓我覺得很有趣,例如「𝟑 𝟛 𝟥 𝟯 𝟹 Ɜ Ȝ Ʒ Ꝫ Ⳍ З Ӡ 𖼻 𑣊」都會變成 3。
而某些字面相同/類似的文字,甚至會出現三四次:
⼒ (U+2F12, 康熙部首 Power) → 力 (U+529B, 中日韓統一表意文字)
カ (U+30AB, 片假名 Ka) → 力 (U+529B, 中日韓統一表意文字)
力 (U+F98A, 中日韓相容性表意文字) → 力 (U+529B, 中日韓統一表意文字)
但 confusables 不像 NFC 標準化只轉換長得一樣的字元,也不像 NFKC 轉換到意義上的標準字樣,而是以視覺上相似的常用字元為主:
ſ (U+017F, 拉丁小寫長版 s 字母) → f (U+0066, 小寫拉丁字母)
ք (U+0584, 亞美尼亞 Keh 字母) → f (U+0066, 小寫拉丁字母)
𝒇 (U+1D487, 粗斜體數學字母) → f (U+0066, 小寫拉丁字母)
延伸閱讀 2:Unicode、UTF-8 差異
這是我困惑了好幾年的問題,以前都把兩個詞混著用,前陣子仔細查過才發現之間差異,因此寫進本文附錄。
Unicode 統一碼
以往台灣用 Big5,簡體用 GB 2312,各語系有自己的一套字元集,資訊流通起來就很不方便,因此有人提出包含所有語系文字、全球都通用的 Unicode 字元集。
在 Unicode 這個字元集中,「你好」可以被表示為「U+4F60, 漢字 you, second person pronoun」跟「U+597D, 漢字 good, excellent, fine; well」兩個字碼;其中 U+XXXX 就是 Unicode 字碼的表示形式,在 Unicode 文件中也會說到這個字碼是「漢字」,代表著什麼意義;而我們平常看到「文字」,則是由字體檔告訴電腦,什麼字碼該呈現什麼圖形。
又例如表情符號「🤪」字碼為 U+1F92A,代表「眼睛一大一小的笑臉」,各家廠商(如 Apple, Google, Twitter, Samsung)再依照自家的風格指南,繪製成 我們看到的樣子。
UTF-32、UTF-16 編碼
在 Unicode 規範中,從 U+0000 到 U+10FFFF 都是有效的字碼,因此如果直接轉換每個字碼到 4 位元組的空間,對程式來說很好實作,這種做法稱作 UTF-32 編碼。
由於多數常用字元都被編排在 U+0000 - U+FFFF 區段,而規範中又保證 U+D800 - U+DFFF 不會對應到任何字元,因此有人想到可以先把所有 Unicode 都嘗試用 2 個位元組表示。遇到 U+10000 - U+10FFFF 區段時,再改用 2 個 U+D800 - U+DFFF 之間的字元(4 個位元組)來表示。
雖然 UTF-32、UTF-16 對程式來說編寫起來很直覺,但無法與 ASCII 編碼相容。即使已知某文字檔只包含 ASCII 字元,對於不相容於 Unicode 的程式來說,可能會因為每個字之間的 NULL 導致無法正常顯示;對於許多以 NULL 作為結尾的語言,甚至連單純的字串複製都無法達成。
假如在不知情的狀況下將 UTF-16 誤作為 ASCII 編碼解讀,就會把「子丑寅卯」解讀為「[PN�[�So」,在某些剛好有定義的字元下,看到時很難斷言這是 UTF-16、ASCII 或其他編碼。
UTF-8 編碼
而 UTF-8 編碼算是解決了這個問題,下圖節錄自維基百科,可以看到 ASCII 範圍的 U+0000 - U+007F 只用了 1 個位元組;而 U+0080 開始,編碼後每個位元組的第一個位元都是 1,即使當成 ASCII 編碼檢視也不會產生歧義。
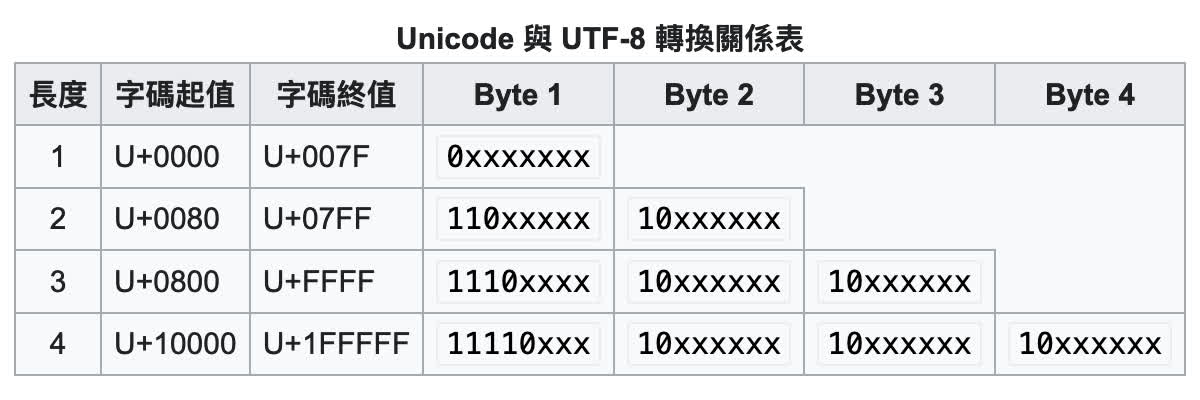
另外蠻巧妙的一點是,後續每個位元組都是 10xxxxxx,第一個位元組則依照字碼長度不同,讓程式從中間讀取字串時,不管是向前或向後尋找字元邊界,都能快速準確的知道該從哪裡切割。
順帶一提,複製網址時常看到的 %E7%B6%AD%E5%9F%BA%E7%99%BE%E7%A7%91 就是中文的 UTF-8 編碼加上 URL Encoding,大多數中文字位於 U+0800 - U+FFFF 範圍內,因此佔 3 個位元組,編碼後 %E7%B6%AD、%E5%9F%BA、%E7%99%BE、%E7%A7%91 各代表一個中文字。
小結
Unicode 是字元集,其範圍從 U+0000 到 U+7FFFFFFF,對我而言算是一個抽象的定義,各個字碼定義了每個「字」的意義、基本形狀,讓字體設計師賦予其活力。
而 UTF-8 是一種 Unicode 的編碼,將 U+XXXX 轉換成 1 - 4 個位元組,讓電腦得以儲存、傳輸。
使用 Unicode 字元集時,不一定要是哪種編碼,在 Unicode、UTF-8、UTF-16、UTF-32 之間可以用數學方式轉換。
在討論 UTF-8、UTF-16、UTF-32 編碼時,用的都是 Unicode 字元集;如果要在 Unicode 與 Big5 或 GB 2312 等字元集之間轉換,則需要有一對一(或多對一)的轉換對照表。
後記
最開始研究時,大家們發現那些看起來正常卻又印不出來的字,只看到 KANGXI RADICAL 康熙部首區段、CJK RADICAL 中文部首區段、CJK COMPATIBILITY IDEOGRAPH 中日韓相容性字元區段,覺得是亂碼。
但根據經驗、實測,瀏覽器 Ctrl-F 搜尋功能又能正確識別出這些文字,因此就從 Firefox 的原始碼 mozilla/gecko-dev 開始找起,發現裡面有一份 confusables.txt。之前 fork 某專案開發時也看過 ICU 相關資料集,因此回去找了正確的上游 Repo,並稍為了解其意義。
原本打算寫成一個 PHP 套件,讓內部專案可以直接 composer install 利用的,但朋友 @splitline 從 GitHub 動態看到我開一個新的 Repo,就跟我分享 PHP 內建的標準化函式,讓我不用重造輪子 XD 在研究完前因後果、經過組內報告後,為了撰寫相關文件頁面,就生出這篇部落格文整理思緒了,希望多少能幫到幾位踩雷的有緣人。
本文撰寫期間麻煩了很多朋友協助校稿,特別感謝 xdavidwu、Thect、Marvin Liu、Cycatz、Alan Kuan 提供寶貴的意見,在討論思辨的過程中,讓這篇文章更精確的傳達科普知識。
本文同步分享於 Telegram、 Twitter、 Facebook, 如果有什麼想法,都歡迎來留言區交流。
References 參考資料
- Unicode UAX #15 標準附錄:unicode.org
- Confusable 易混淆字元:unicode-org/icu
- Unicode 字碼資訊:fileformat.info
- 維基百科:Unicode、UTF-8、Unicode 區段、字元編碼