前情提要
這學期修習黃俊穎老師開設的網路程式設計概論(網程設),前半學期教了如何用 TCP 從簡單的 socket 應用,到實作較為複雜的 IRC 伺服器。
這次第 12 周的實驗內容讓大家用兩週的時間,寫出能抵抗惡劣網路環境的 UDP 程式,完整傳送 1,000 個平均 16 KB 的檔案。
實驗限制
這次評測端使用 tc-netem (8) 製造出不穩定的網路環境,限制如下:
- 封包有 40% 機率會遺失、10% 機率損毀
- 延遲 50 ms - 150 ms
- 網速上限 10 Mbps
- 封包大小上限 1,500 bytes
在這樣的環境下,如果不特別做處理,基本上是傳不了檔案的,也因此是考驗各組技術的地方。
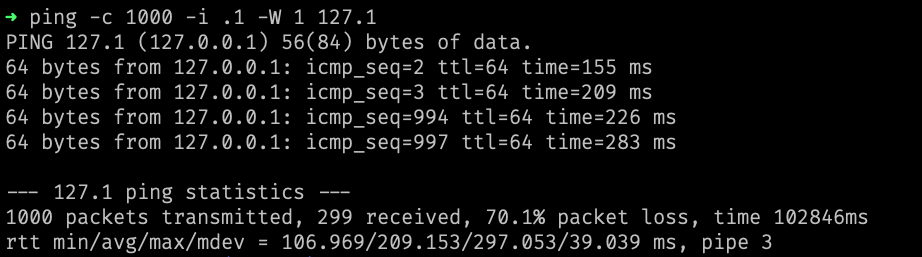 |
|---|
| 使用 ping 測試的結果(封包來回需乘二) |
最初的想法
在開始寫程式之前,當然是要先設計自己的通訊協定原型。原本規劃好了整套如何取得目錄、如何得知檔名及內容的協議,不過愈想愈覺得在這次的實驗中,分檔案慢慢傳反而沒效率。
因此後來決定把寫好的協議及寫到一半的程式碼全部刪掉,從頭開始設計當成單一檔案傳輸的方法。
封包結構
實驗環境 MTU 只允許每個封包傳送至多 1,500 bytes 的內容,因此會需要切成不同區塊,本次設計的封包結構前 2 bytes 是區塊編號。
每個小封包扣掉 IP 層標頭的 20 bytes 及 UDP 層標頭的 8 bytes,再扣掉 2 bytes 的區塊編號後,共有 1,470 bytes 可供存放資料。
在我的作法中,是先合併出一個大封包。大封包最前面的數字是總區塊數,後面接著 1,000 個數字是各檔案的尺寸,再來各檔案內容直接連接在後,以節省填充內容佔用的空間。
也因為老師保證檔案大小在 32,000 bytes 以下,最極端的例子封包數也不會超過 22,000 個,因此只需要 2 bytes 的空間(-32768 ~ 32767)即可儲存。後面再接上所有檔案,合併後一個大封包總共約 16 MB 大小。
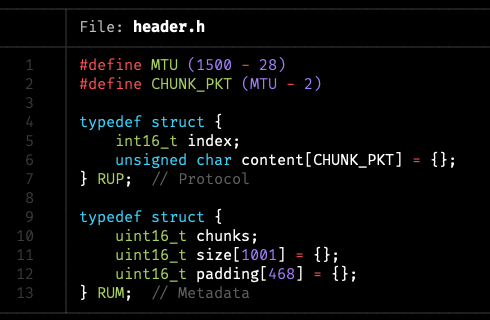 |
|---|
| 本次定義的標頭檔 |
傳送邏輯
在相當穩定的環境下,我們可以只傳送不確認;在反應迅速的環境下,我們可以等收到確認封包再進行下一步;但在這次既慢又不穩的環境下,兩種做法效率都不會太好。
因此我採用的方式是發送端自行估算在恰好頂到速度上限時,每隔多久可以發送一個封包。
而接收端確認的方式,則是定期告訴發送端目前順利收到哪些封包了。
發送端詳細邏輯
對發送端來說,如果封包傳得太急,會踩到 10 Mbps 速率上限,導致緩衝區愈來愈長,封包需要排隊才能送出。
如果因此造成多餘的延遲,讓確認封包也塞在緩衝區,最終導致無謂的時間浪費和送出更多重複的區塊,因此我們要找出適當的發送頻率以達到最佳平衡。
以我的實作來說,每個封包都是吃滿 1,500 bytes 上限,多數流量來自發送端,來自接收端的確認封包佔少數。
在撰寫本文之前,埋頭寫程式都沒去認真計算理論值,經過測試得出發送端大約需延遲 0.756 毫秒,恰好是碰到速率上限的甜蜜點。
對於總共 16 MB 的檔案,為了符合最大傳輸上限 1,500 bytes 限制,分割後大約有 11,500 個區塊需要傳輸。
最開始接收端什麼都沒有,因此先全部都發送一輪(約需 8.5 秒),之後再透過接收端回傳的確認封包,看哪些區塊未順利送達,再次依序發送。
理想狀況中,每輪需要發送的區塊數量減半,所需時間也跟著減半。不過加上考慮延遲後,大約第六七輪開始,確認封包會來不及回傳。
接收端詳細邏輯
發送確認封包的方式有許多不同做法,依筆者心中的效率簡單排序,由低到高大致為:
- 收到每個區塊時,都單獨回傳確認(可能較差)
- 收到數個區塊後,用一個封包,批量進行確認
- 每隔一段時間,用多個封包,回傳伺服器的完整狀態
- 每隔一段時間,用多個封包,回傳所有收過的區塊編號
- 每隔一段時間,用一個封包,回傳新收到了哪些區塊
- 每隔一段時間,用一個封包,以 bitset 回傳伺服器狀態(可能較佳)
因此在最終的版本中,我是以 bitset 形式回傳接收端的狀態,每次只需要一個封包即可完成。
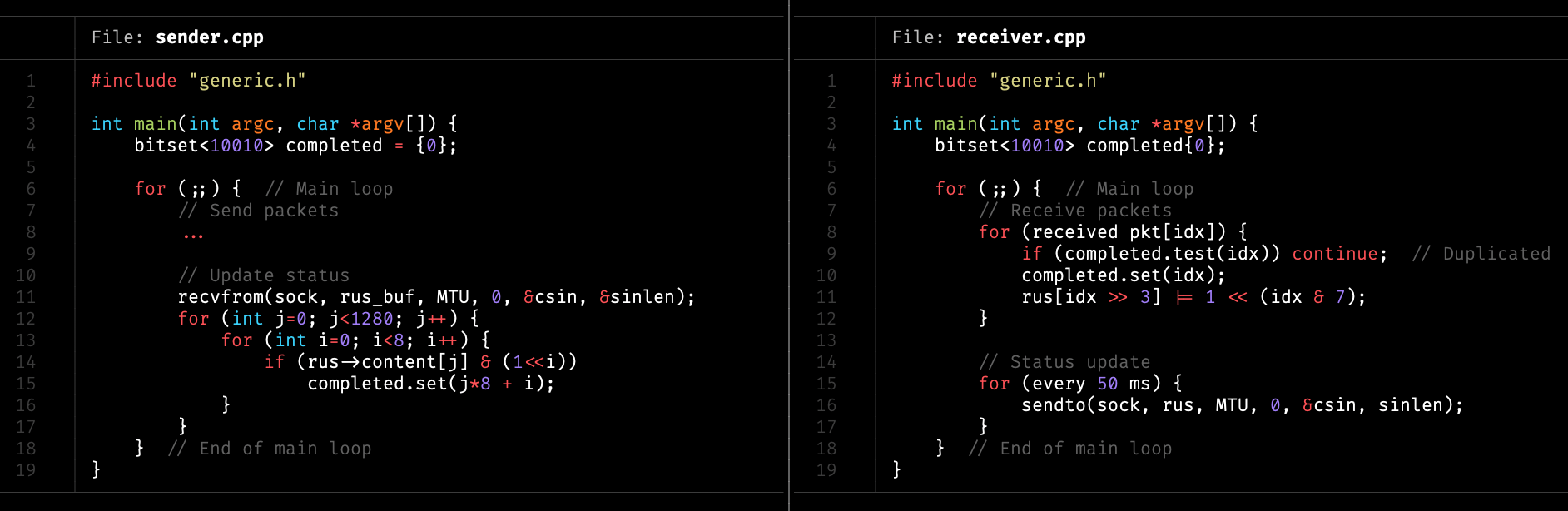 |
|---|
| 使用 bitset 儲存、傳送狀態 |
有思考過在最後剩下不到 500 個未完成區塊的時候,或許直接回傳近期收到的區塊編號可以再更節省流量,不過感覺實作相對麻煩就作罷了。
延遲詳細計算
已知條件為:
- 每個封包 1,500 bytes
- 速率上限 10 Mbps
- 約有 40% 機率遺失封包、10% 機率損毀
根據定義可以計算:
(封包大小 1,500 bytes) * (單位轉換 8 bit / byte) * (成功率 60%) = 平均封包大小 7,200 bits
(速度 10 Mbps) / (封包 7,200 bits) = 每秒可傳送 1,388.88 個封包
1 / (每秒 1,388.88 封包) = 每封包間隔 0.72 毫秒
雖然理論值是這樣,不過因為 tc-netem 實作的關係,似乎 0.75 毫秒才是最佳延遲,實驗及試算了好久都不知道怎麼得出正確數字。
檔案壓縮
原先在 Discord 嘴砲說想直接用外部函式庫完成這次實驗,想說既然都讓老師把檔案亂度增加了,那應該是不需要玩壓縮的技巧。
 |
|---|
| 於 Discord 詢問使用壓縮函式庫 |
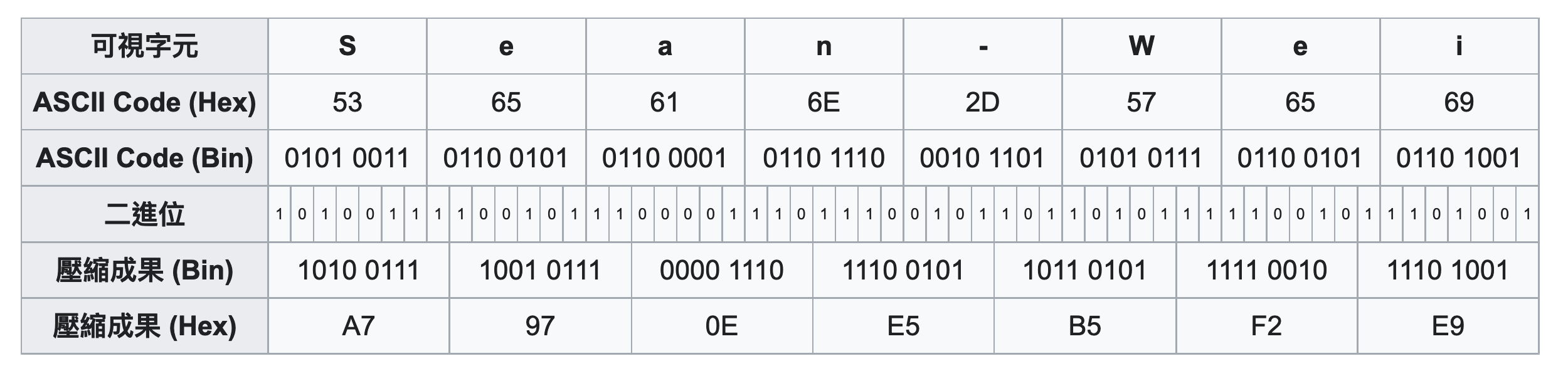
不過後來得知檔案內容只包含可視字元,轉換為 ASCII 是 0x21 到 0x7E 的區段,在每個 byte 中 256 種可能中只佔了 94 種。
在此假設檔案亂度不低,也就是外部壓縮函式庫幫助有限,因此採用類似 base64_decode() 的方式將檔案從可視字元區段映射到整個空間。
最簡單的做法當然是取消最前面固定為 0 的位元,只要透過簡單的位元運算,就讓每 8 個可視字元字映射到 7 bytes,節省 12.5% 空間。
 |
|---|
| 每 8 個可視字元可映射至 14 bytes |
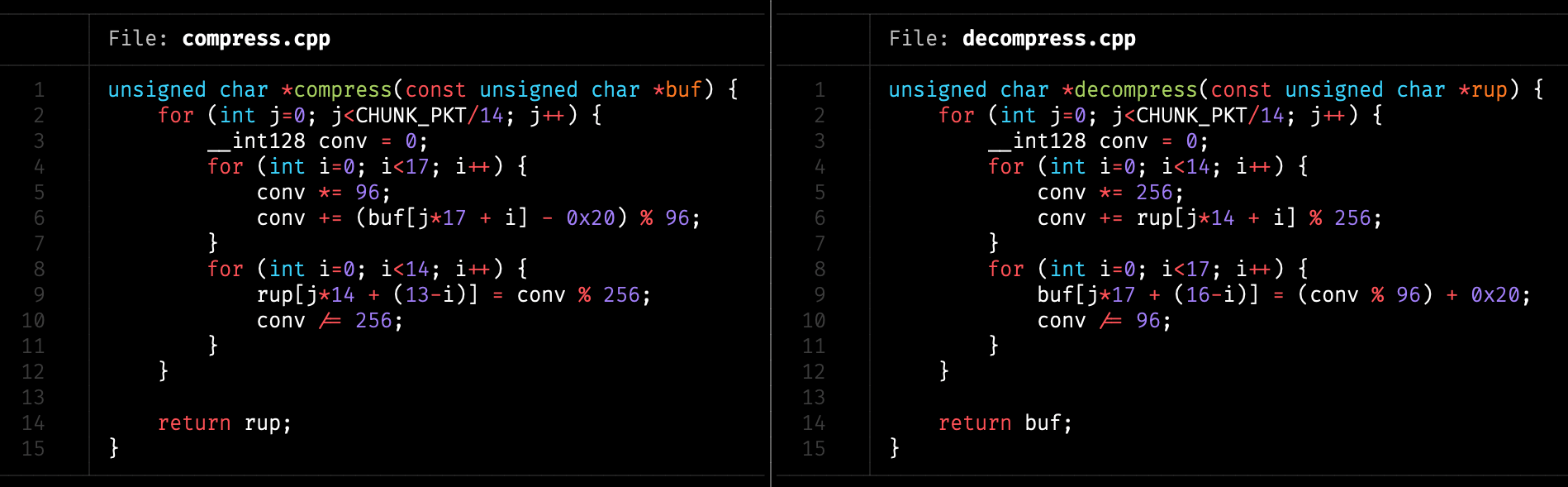
經過計算後,發現可以透過運算,把每 17 個可視字元映射到 14 bytes,省下了 17.6% 的空間。而運算過程中,剛好勉強低於 __int128 的上限,實作起來不算複雜。
如此讓每個封包 1,470 bytes 的內容實際可塞下 1,785 個可視字元,封包總數量減少到 9,500 個。
 |
|---|
| 把每 17 個可視字元映射到 14 bytes |
在最極端狀況下,每個封包其實可以塞下 1,794 個可視字元:
(log(256) / log(94)) * 1470 = 1794
雖然可以省下 18.1% 的空間,不過實作起來會困難許多,因此沒有採用此方法。
減少多餘等待時間
在經過分析後,發現原本的程式最前面將檔案合併成大封包,再分割成 9,500 個區塊的過程中,大約會耗費 500 毫秒的時間,因此改為邊切割邊發送第一輪封包。
而接收端如果在結束前才一次寫入,會耗費大約 350 毫秒的時間,發現後改為判斷接收完一個檔案就寫入一次。
另外由於評測的機制是發送端結束後,會強制關閉接收端並開始比對檔案。因此發送端不能太快結束,但太晚結束又會影響表現。
後來測試出接收端在剩下大約 5 - 10 個區塊未完成時,提前傳送關閉指令是較為折衷的作法。
動態調整發送間隔
為了進一步最佳化性能,在接收端回傳狀態封包時,也順便帶上當下的時間戳。
發送端可以用來計算單向的延遲,判斷緩衝區是否已被塞滿。
原本有實作根據延遲時間自動調整間隔的功能,不過由於延遲是隨機在 50 - 150 毫秒之間飄動,事後證實效益不大。
後來改為使用理論值來計算發送間隔,可以達到較穩定的效果。
沒用到 UDP 的玩法
從看到實驗限制後,就有想到或許可以透過指令列參數,利用側通道傳送資料,不過覺得做起來稍嫌麻煩,因此一直沒有動工。
在正規作法進步到 13.08 秒,想不到可以怎麼繼續加速後,就決定來實作看看,完成後還真的得到比當時第一名還快 70 倍的破表分數。
雖然有股想要壓到 0.02 秒以下的衝動,不過畢竟初衷只是確認可行性,還是決定先就此打住。
| 當下計分板 0.18 秒成績 |
評測方式
評測平台會建立 /sender_dir/ 及 /receiver_dir/ 兩個資料夾,並將發送端及接收端的執行檔分別置於 /sender_dir/sender_bin 及 /receiver_dir/receiver_bin。
在 /sender_dir/files/ 資料夾放有 1,000 個隨機檔案,執行結束後會檢查是否成功傳輸至 /receiver_dir/files/ 資料夾。
以發送端來說,先使用 chroot("/sender_dir/") 防止執行環境存取外部檔案後,再執行 /sender_bin --read-from="/files" --send-to="localhost:4242" 指令啟動。
接收端則是以 chroot("/receiver_dir/") 限制環境後,再執行 /receiver_bin --listen-port="4242" --store-to="/files" 指令,將透過 UDP 協定收到的封包儲存至 /receiver_dir/files/。
本題是限制網路層的傳輸速度,應該有不少做法作法可以繞過,我只挑自己較為熟悉的一種來實作。
cmdline 簡介
我是從 2021 年 4 月在調研 ldapsearch 資安漏洞時,翻閱原始碼而接觸到這件事的,不過後來發現因為有盡最大努力側面修補,攻擊雖然可行但時間點需要抓得很精確,因此後續不了了之。
知道 cmdline 這種玩法後一直覺得很酷,或許寫成一篇科普短文也還不錯,但這裡為了篇幅就只講重點。
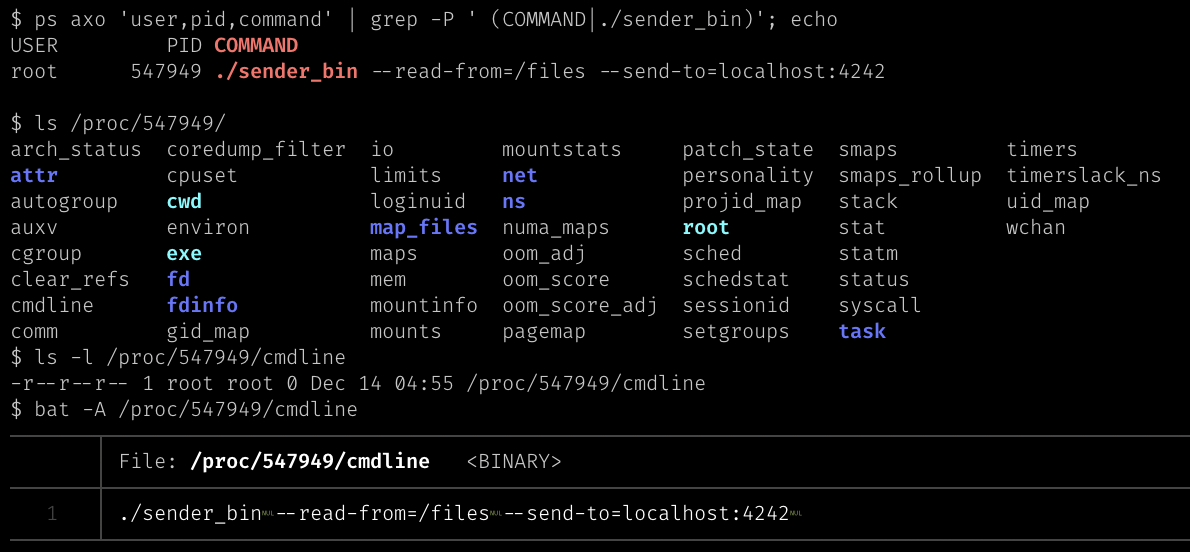
熟悉 Linux 的大家應該都用過 ps aux 指令,但知道其中實作方式的人可能不多。
在 Linux 系統根目錄底下有個特殊的 /proc/ 資料夾,存放核心(kernel)的相關資訊,而底下以程序編號(Process ID)命名的資料夾則存放各程序的狀態。
例如 /proc/[PID]/fd/ 底下以數字命名的檔案,會連結(symbolic link)到程式開啟的各個檔案;而 /proc/[PID]/cmdline 檔案則寫著被執行時的參數,以 0x00 (NUL) 字元區隔。
這個 cmdline 檔案雖然無法直接修改,但程式可以透過 prctl()、pthread_setname_np() 更動,或直接修改 main() 函式收到的 char *argv[] 內容也會反映在上面。
 |
|---|
| 透過 cmdline 查看指令參數 |
作法說明
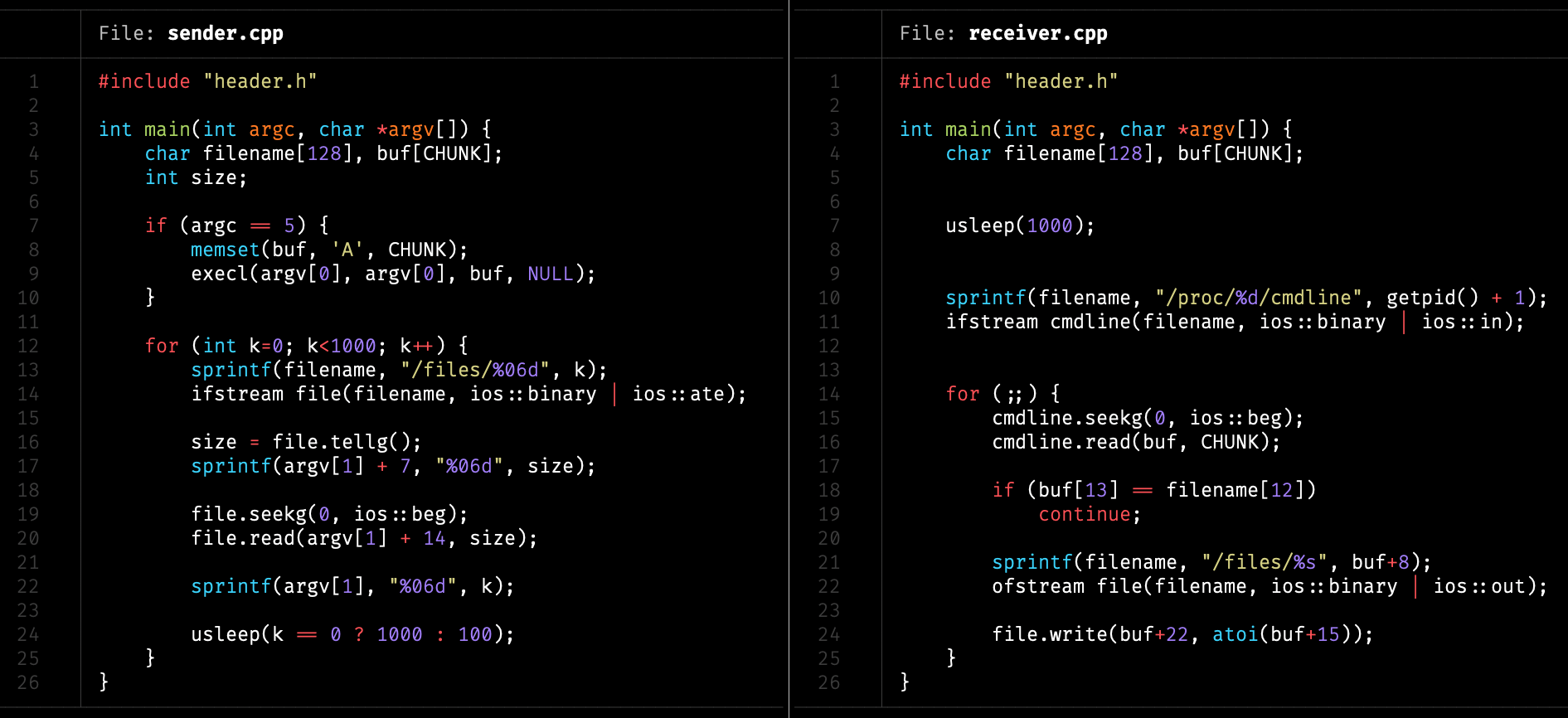
在通常狀況下,main() 收到的 char *argv[] 長度也就幾十、至多幾百個字,如果要拿來傳資料顯然效率不足。
這時可以透過上面提過的函式更動,不過在此為了簡單實作,採用之前學過的 exec() 呼叫自己,並在 argv[1] 傳遞一個很長很長的參數,目的是擴充 cmdline 檔案大小,才塞得下整個檔案內容。
在完成後就能自由運用 argv[1] 參數了,開始每隔 0.1 毫秒更新一次 argv[1],依序將檔案內容放上。這會同步到 /proc/[PID]/cmdline,也就是 ps aux 指令會看到的結果。
而接收端則是先等候一小段時間,先確保傳送端已啟動後,持續檢查位於 /proc/[PID]/cmdline 檔案的參數內容,如果有異動就寫入 /receiver_bin/files/[ID] 目標檔案。
 |
|---|
| 使用 argv / cmdline 繞過限制傳送 |
使用這個方法,理論上可以再 fork() 出不同程序(process)同步執行,用到本題上限的 15 個程序可以加速不少。
也可以把間隔時間依照檔案大小自動調整,或是讓接收端發出訊號,減少不必要的等待時間。
後記
寫這個實驗的過程中,心中一直被「執行效能」的想法所侷限,但仔細思考後認知到在這個場景下,最珍貴的資源是網路而不是 CPU 效能,有許多顯然花費不合理運算的事情實際上卻可以增進執行效率。
老師在隔週的課堂也說了,原先沒想到大家會把時間用在最佳化上面,因此乾脆將一堂實驗課讓出來,給同學們分享各自作法的機會。
雖然有做好 簡報,
不過由於剛好要 參與資安檢測,
當周課堂無法出席報告,經過老師同意只好以 預錄影片 代替。
感謝 Thect、
yc油成、
Jerry Hsu、
CTFang、
Sirius Koan、
TwinkleStar03
等朋友協助審閱文章提供建議,指出盲點讓文意更通順。
對於文章有任何想法,都歡迎來 Twitter、
Facebook
留言交流,或是在課堂實體捕捉我。
如果想嘗試的朋友,老師也在課後將 實驗題目規格 公開,歡迎參考練習。